Physical standards are amazingly foundational things that we frequently take for granted. I can buy a 1/4-20 bolt today and fit it into machines built many decades ago. There is a variety of tooling readily available to work with threaded bolts: wrenches, impact drivers, torque wrenches of all kinds, thread gauges, taps and dies, threaded inserts.
Importantly, this is all astoundingly cheap. An individual bolt might just be a few pennies, barely more than the cost of raw materials. Wright’s Law states that for every cumulative doubling of units produced, costs tend to fall by a constant percentage. The more we make of something, the cheaper it is per-unit.
The volumes and competition generated by a shared standard push us further up the experience curve than would be possible if each company produced their own bespoke product. We can build bigger, faster, more specialized tools and amortize their cost over more usage.
Standards enable investment.
While we operate under different constraints, the same is broadly true in software. One-off solutions can be eye-wateringly expensive, but standards make for cheap and plentiful tooling.
Today’s tools
When it comes to understanding and introspecting our systems, our industry has been a bit of a wild west for a long time.
Mostly we rely on vendors. Vendors build SDKs that bend over backward to automagically wrap libraries and generate mystery payloads that get shipped off to proprietary services. This usually exists as an opaque layer on top of our software. We get trained that instrumentation is someone else’s responsibility, too complicated for us mere mortals.
This can be great for the handful of vendors that manage to win a majority of the market, but it’s a pretty bad experience for everyone else. Additionally it draws hard limits on what’s possible.
You’re never going to get Django to build in Datadog support. AWS is never going to integrate New Relic into its platform. And if they did, this would only entrench that handful of vendors even more.
Without standards in this area all investment in the tooling comes from vendors who all end up re-building very similar things. It’s hard or economically treacherous for others to build on top of their proprietary stacks. The lack of standards prevents broader investment.
We’re trapped in a local maximum. Open Standards provide a way out and, hopefully, a better experience.
Today’s experience
When I deploy a web app built on a common stack today (say: Rails and Postgres) whether on a cloud, PaaS, or my own hardware I get precious little information about what my software is doing. I may get some basic HTTP, memory, CPU metrics, but if I want more fine-grained data I’ll need to go elsewhere and start from scratch.
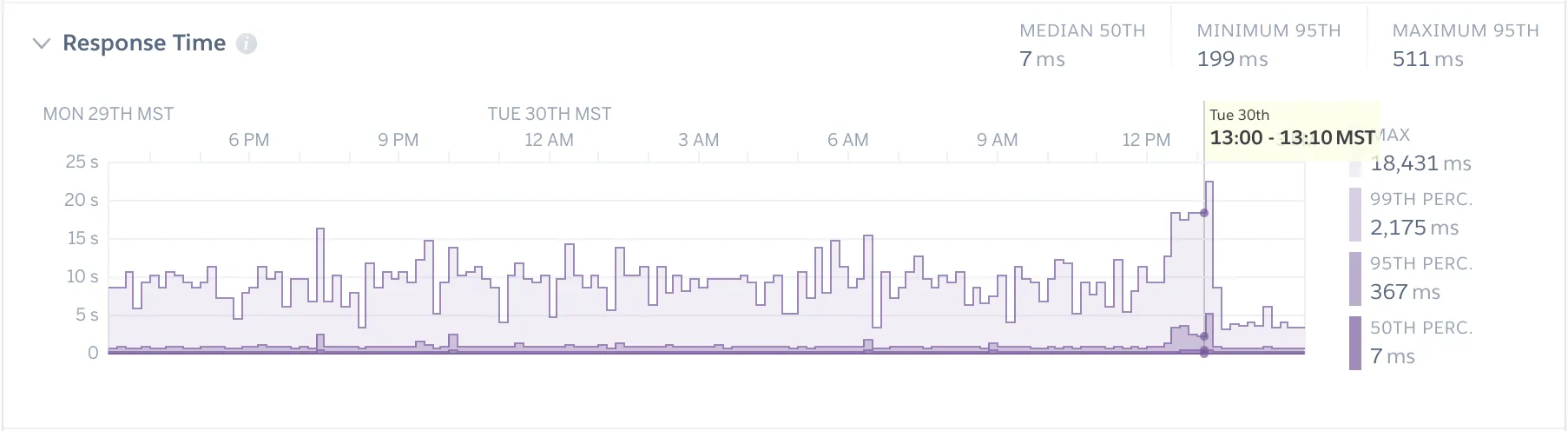
This is in sharp contrast to the detailed information about each HTTP request or database query we get in an
APM tool like New Relic. Want to see the slowest requests on the /checkout endpoint filtered by region
and device? New Relic likely has you covered. Need to see your slowest database queries? It’s only a couple
clicks away!
Fair play to New Relic, it took a lot of exceptional engineering to make this look seamless! What if the next company didn’t have to build all of this from scratch? What if we could expect more from our tools in the first place? Rails can easily capture all of this information. Why do we need a vendor to write fancy code to wrap it and surface it to us? Wouldn’t the instrumentation likely be better if the Rails developers designed the instrumentation for their own code?
Prior to OpenTelemetry there hasn’t been a clear mechanism for doing this. Imagine I’m writing a database client library
and want to communicate to my user’s system an observation like query X took 1.2ms, returning 152kb of data across 200 rows. Without a standard way of emitting this data, I don’t have many good options. I could
write log messages to stdout, but they might not be formatted the way the user needs. I might build a plugin
system so the user could bring their own logic, requiring more work from the user and making my own library more
complicated in the process.
A vision for the future
What if I could build instrumentation directly into my code and the user could configure what they wanted to do with it? It might look like:
class Database
def execute(sql)
in_span("sql_query") do |span|
# execute the query
span.set_attributes(
"query" => obfuscated_query,
"results_size_kb" => results_size,
"results_row_count" => results.length,
)
end
return results
end
endThat already exists! It’s the OpenTelemetry API. It’s not even directly tied to the OpenTelemetry OTLP format, and you could use this instrumentation to generate a completely different trace format or even just log lines if you wanted.
Let’s go a bit farther and imagine a better future where all of our dependencies come with re-usable instrumentation, where profileration of a single standard mean our IDE, platforms, languages, and frameworks call all work seamlessly together.
When building my service locally, I have local tools to view the telemetry my service is emitting,
perhaps they’re even built into my IDE. When I deploy to a PaaS service, it automatically collects and surfaces traces, metrics, and
logs right in the dashboard. Maybe the platform automatically pulls in more metadata for me so I can easily view how my requests are performing as a new versions roll out,
or how my latest changes affected response times in Germany, or notice a spike in errors on the /account/:id/details endpoint and jump to an exemplary trace.
A few button clicks later and now this data is flowing to my preferred Observability vendor as well as our own data warehouse for deeper analysis and long-term storage.
I haven’t had to write a single line of code to enable this, or stand up any custom infrastructure, and I don’t even really need to know how it’s happening. Like my IDE debugger or the Chrome Dev Tools, it’s just another tool that I expect to work. However once I discover that I do need some additional data, there’s a standard and easy way of extending the data my frameowrk and libraries are creating for me.
OpenTelemetry is usually sold as a way of avoiding lock-in for Observability vendors
[1],
but that’s just a start. If the standard is successful it’ll also be built into libraries, frameworks, tooling, IDEs,
languages, and platforms. For many users it’s likely the standard
will mostly disappear into the background and become an expected part of the system.
We’re still very early on this journey as an industry with OpenTelemetry.
what I really want to see are framework-level “batteries included” sdk reimplementations on top of the OTel APIs.
spiritually similar to how rust has coalesced around the tracing crate with pluggable exporters
— austin 🎄 (@aparker.io) December 14, 2024 at 1:21 PM
But is OpenTelemetry the right standard?
How do we know that OpenTelemetry is the right standard to bet on? Don’t some people have problems with it? Isn’t it “design by committee”?

David Cramer had a popular post about his issues with OpenTelemetry, and Ivan Burmistrov brought up a number of points in All you need is Wide Events, not “Metrics, Logs and Traces”. Hazel Weakly recently dove into one of OpenTelemetry’s biggest flaws: lack of a standard for long-running spans. I generally agree with most of their points! [2]
If your main experience with OpenTelemetry today looks like a more tedious, worse version of adding an APM vendor I don’t fault you for taking this view. I’ve even cautioned people away from adoption today if they have a small team or are under a lot of pressure. (My wide events guide can help though!)
OpenTelemetry is a really important project, but if you’re in a place where you are struggling to understand your systems, trying to adopt OTel as a way out is: - likely not going to solve your problem - going to give you heaps more complexity to navigate
— Jeremy Morrell (@jeremymorrell.dev) April 20, 2024
OpenTelemetry is complicated and endlessly extensible. That comes as a necessary byproduct of supporting so many different stakeholders. What looks like unnecessary bloat to you frequently turns out to be core to someone else’s adoption. That complexity enables everyone to get on the same page.
It’s not perfect, but it is succeeding at the main thing a standard needs: wide adoption. OpenTelemetry has shown major uptake by vendors and is starting to be adopted by end-users in enterprise. OpenTelemetry is the 2nd most active CNCF project after Kubernetes. There is clear momentum and no obvious competitors.
The benefits from having a single standard, and what we could build on top of that foundation, far outweigh the drawbacks in complexity. We should be very thankful that the creators of OpenCensus and OpenTracing decided to collaborate rather than compete.
OpenTelemetry is not a monolith
OpenTelemetry can be the foundation of this better future, but it’s not a certainty yet. It’s a big, sprawling specification, and it can be helpful to break down how each part contributes to the whole.
Caveat: Most of my experience is with the Ruby, Go, and JavaScript ecosystems. Things may look different in other languages.
OTLP
If a vendor supports receiving OpenTelemetry, usually that means they support receiving OTLP formatted data. All of my interactions with the OTLP format so far (mostly tracing and metrics) have been good ones. It’s not very hard to generate from scratch, and there is good library support for both generating and parsing this data.
There are a growing number of tools
to visualize and work with this data locally, and I hope this trend continues. No one should
be debugging traces and metrics by squinting at serialized data structures dumped to their terminal.[3]
My most pressing request for OTLP is an official way of representing unfinished spans similar to the span snapshots that Embrace is using in their mobile tooling.
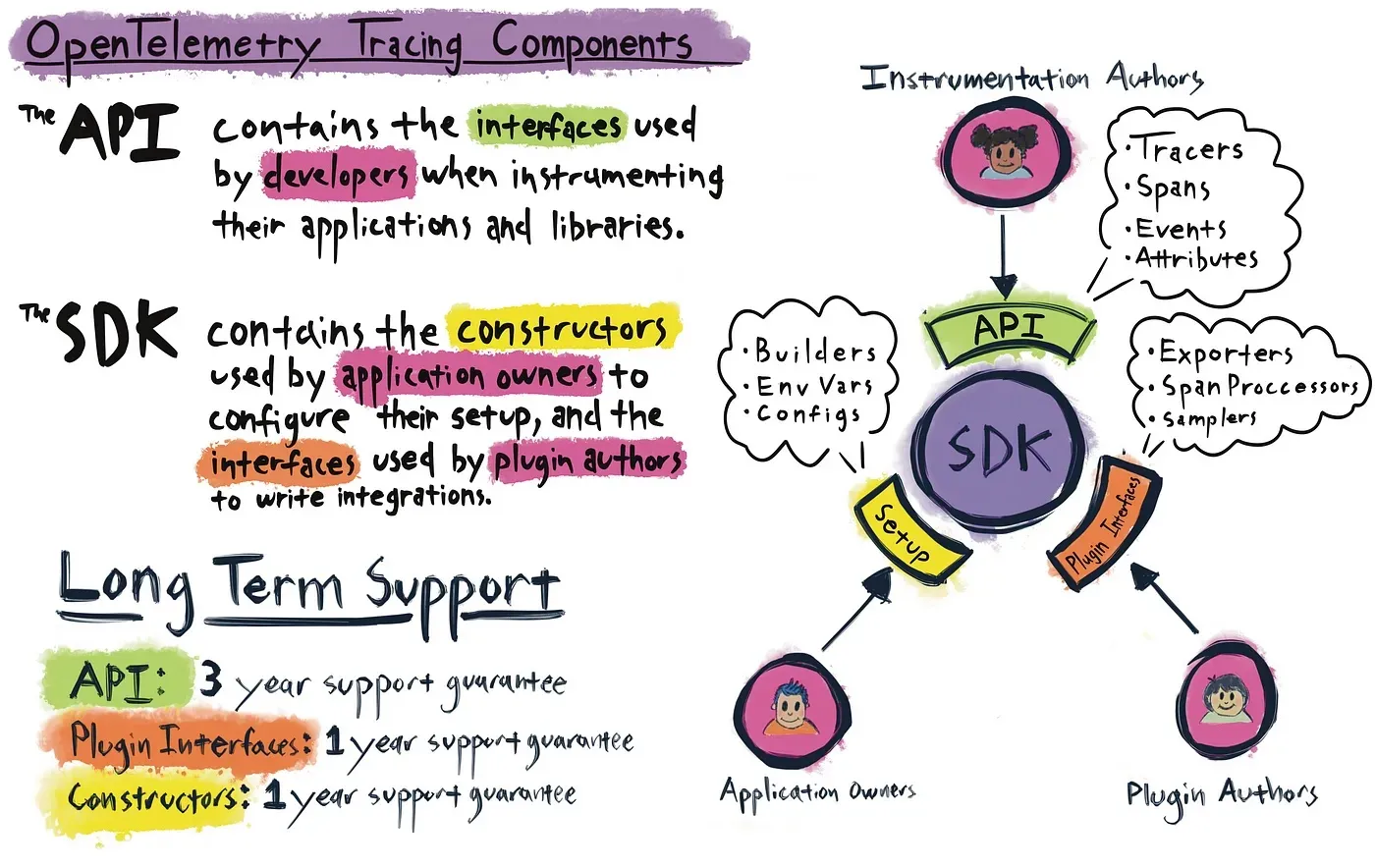
API
The split between the API and SDK in OpenTelemetry is not well-understood, but is one of the most interesting ideas in the project.
The API is a small set of interfaces to create traces, metrics, logs that have no implementation, just a hook that the end user can use to register their desired behavior. The OpenTelemetry SDKs build on these interfaces, but nothing is stopping others from doing the same thing. If library authors embed them into their code, then we can avoid needing fancy Instrumentation libraries.
I mainly have experience with the tracing and context APIs, and find them fairly straight-forward to use, if not always the most idiomatic.
Ultimately I think that these APIs are good candidates for getting folded into the language itself. Rust is leading the way.
SDK
If you have added OpenTelemetry to your service, the library you installed was the SDK. It’s a full-featured, configurable toolkit for instrumenting your code and emitting telemetry. You can think of it like the Sentry or New Relic libraries, though a better analogy might be a toolkit you could use to build those libraries.
I’ve had very mixed experiences with the OpenTelemetry SDKs.
They are amazingly extensible and battle-hardened bits of software. Even when handed really weird requirements, I was always able to find a way to get them to do what my company needed them to do. I’ve only experienced one or two production issues even after years of using them at scale. The maintainers should be incredibly proud of their work.
However it’s not all sunshine and rainbows. The documentation is not always the best, and I frequently find myself digging into their code to figure out how something works. The SDKs introduce many concepts to the user and require lots of configuration even on the simplest happy path. When compared to a polished, opinionated vendor experience it’s clear that the SDKs don’t measure up.
I’d like to see a better default experience. When I printf to stdout I see the data immediately and
without configuration in my terminal. I can easily pipe this to a file. It shows up in my IDE. My deployment
platform likely has first-class support for collecting and sending this data to a vendor of my choice. I want that same ease-of-use for OTLP streams.
I fear that we are moving away from this vision and towards even more layers of configuration.
Collector
The Collector is configurable glue, a swiss army knife that can morph into whatever your organization needs. There’s probably a plugin that converts from whatever you have to OTLP and back again. If there isn’t, writing a custom one isn’t too difficult. It allows an organziation to gradually adopt OpenTelemetry in their existing systems and makes building centralized tooling to handle telemetry streams more tractable.
I think the Collector is a large reason for the success organizations are having in adoption of OpenTelemetry. People love deploying collectors! Perhaps too much. It’s easy to turn around and realize that you have more than a dozen in production, all somehow justified.
In a future where OpenTelemetry has become a standard I think there will be less need of the Collector-as-glue, but I still see it living on at the heart of many toolchains.
Contrib
The SDK provides core functionality, and the contrib collections provide plugins and adapters. This is where you find OpenTelemetry’s Rails instrumentation or Node’s Postgres client instrumentation or plugins for the collector to receive legacy formats.
The contrib instrumentations represent gobsmacking amounts of engineering effort. This code can be really difficult to write and maintain, especially as the underlying library evolves and changes. Navigating breaking changes and which version is supported by which contrib version can be a real pain. Despite that I’ve mostly had good experiences with these!
However I would like to see a future where they largely aren’t necessary because vendor-neutral instrumentation has been added directly to the libraries or other systems themselves.
Semantic Conventions
Semantic Conventions is the idea that every time your are instrumenting a similar thing, such as an HTTP service or a job queue, the
telemetry emitted should look the same, have the same shape as telemetry from other HTTP services or job queues. The status code
for an HTTP response should always be http.response.status_code, not http.status_code, not http_status_code, not statusCode or status-code.
While technically the simplest, in my opinion Semantic Conventions is one of the most ambitious OpenTelemetry specs. If broadly adopted it will allow tooling to recognize patterns and surface much better information for users. However trying to name so many things across so many domains is an incredibly difficult thing to achieve, let alone getting buy in across so many implementations.
[1] I suspect vendor neutrality is over-hyped relative to its actual merits. From experience migrating an org with a non-trivial number of systems, alerts, dashboards, and integrations with other systems, and hundreds of engineers who need to learn how to use the new vendor, double-writing telemetry into the new system is not the hard part.
While it does provide some insurance against a vendor charging you extortionate rates, for most organizations migrating vendors could cost on the order of millions of dollars in salary and months of time in opportunity cost that could be have been spent improving the core product. And that’s if the organization has the engineering maturity to organize this kind of migration in the first place, many do not.
Choose your observability vendors with the same care with which you choose your cloud provider, whether you use OpenTelemetry or not.
[2] In particular, I generally agree with Ivan Burmistrov’s points in All you need is Wide Events, not “Metrics, Logs and Traces”. A span is an event. A set of metrics can be an event. A log is an event. An event attached to a span is… another event.
OpenTelemetry creates a lot of complexity that seems unnecessary from this perspective, but I suspect a simpler event-based model would never have been adopted by any traditional vendor. Without wide adoption, it would very likely fail as a standard.
[3] I’d like if
the OpenTelemetry project itself provided more tooling here though those discussions seem to have fizzled out.
And please do not make me run a heavy-weight production tool in docker to visualize my telemetry. Give me native apps, CLI tools, IDE plugins. Treat this as a first-class concern because it shapes so much of the users’ experience.